Branching for atomic patches and cherry-picking
The best thing about Distributed Source Control Managers ( IMNSHO ) is how quick and easy it is to branch and merge. The problem is that most of us cut our teeth on centralized systems that couldn’t even hope to take advantage of cherry picking, which is, in short the ability to take a single patch out of the middle of a sequence of patches, or every patch but one from a sequence. Just imagine knowing that there was a bug introduced in a specific patch and being able to prune it from your repository but not any of the patches around it. Or, plucking one little feature out of a mass of others that should wait until the next release. You can, but if you don’t make the effort to keep your patches as atomic as possible you’ll find that that patch you want to remove or extract is dependant upon another one, or more, that you may not want to involve.
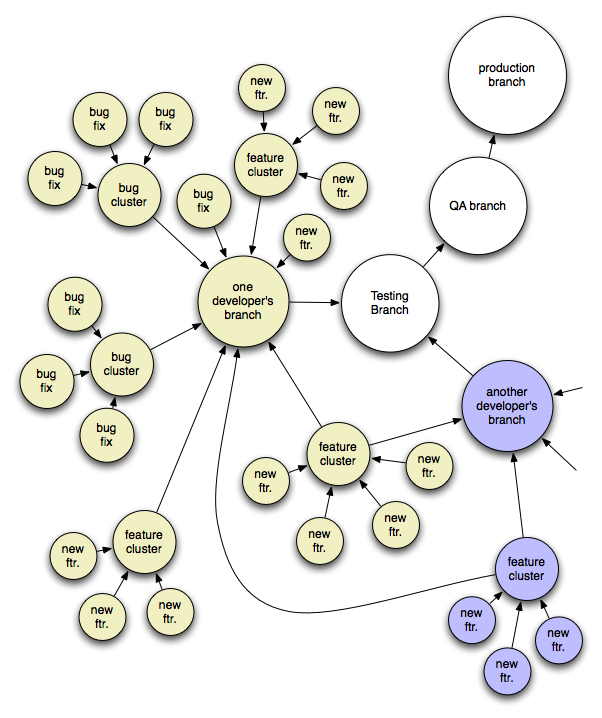
Which brings me to my hierarchy of branches. Now, I’m still working with this concept so if you can improve upon it please let me know. The idea is that most of the time you’re not adding one little atomic feature, you’re adding a number of features that can be conceptually clustered. So, you make a branch for the cluster, but do no actual development directly in it. Then you branch from there for each atomic feature (be sure to scroll down to the graph below the fold here).
While you are working on a feature feel free to commit as often as you want. Check in broken or unfinished code. Pollute that branch’s revision history with as much crap as you want. Do whatever it takes in there to make sure you can roll back to any point you want, and never loose work. Have a cron job check in any uncommitted changes to this micro-branch every night in case you forget to. It doesn’t matter because you’re not going to push the revision history back up to the branch for the feature cluster. Instead you diff from the branch point and patch the cluster branch and commit it. This way you’ve got one atomic revision with the combined changes for that one small feature and if you need to prune it for any reason (maybe it’s broken, or decided you should wait on adding it) you can easily do so without worry of dependencies. Your micro branch has all the details of the feature evolution if you really feel you need it, but most of the time you’ll just delete it after creating the patch and applying it to the cluster. Eventually the cluster will have all the related features completed and checked in and it’s revision history will consist of a series of atomic commits. The cluster’s revision history is then pushed upstream to your personal development branch. Occasionally you’ll have a small feature to work on with no related ones to cluster. Just branch from your personal development trunk and then patch back into it as you would have into a feature cluster.
Bugs should be treated in exactly the same way as features, although you’ll find yourself with many more small bugs that don’t need a parent cluster and can just be worked on in their branch and then used to patch your personal development branch.
People working farther upstream now have the option of cherry picking features, feature clusters, bugs, and bug clusters, and will be able to do so with much less worry of getting caught up with patches that depend on other patches.