New Year New Tools
Holidays == time to code!
We had to drop our car off at the dealership last night. In order to avoid walking home in the dark, on roads without sidewalks, in 27°F (-2.7°C) - or just the last two shortly after dawn, we needed to drive the 🚑 Ambulance. Unlike most years, I actually remembered that it had a block heater1 and had turned it on at the beginning of winter.
Following on the heels of my last post on why you should (not) self host your git repos, I went ahead and used Gitea to set up a local mirror of all my repositories, and all the repositories I don’t want to loose access to.
The results were surprising, and after reading this, you might want to do the same. This post will be a qick overview of how I did it, some tips that’ll help, and what I learned as a result.
Once upon a time, GitHub was a successful geek enterprise. Then Microsoft bought it, and folks started arguing that you should abandon ship. You should self-host your repos they say.
I 100% agree, and 100% disagree. Let me explain.
GitHub’s been a benevolent host. When they bought NPM they went from being a de facto piece of internet infrastructure to an actual piece of critical infrastructure. At this point you may as well argue that we should sever our connection to the electric company.
For the past decade or so, I’ve noticed a trend amongst my coworkers. When they need to look at the contents of a file that they’re not currently editing, they will go to GitHub, and click their way down through the folder structure until they eventually find the file they want to see the contents of.
On a related note, I believe that most of my coworkers don’t know how to take a relative path in a repo, and tell their text editors to open it.
GitHub recently announced GitHub achievements. It’s a great idea, but I’m really left scratching my head by what the achievements are.
The “Pull Shark” is open pull requests that have been merged. I’ve got a “4x” version. 4x makes NO sense to me given the number of repos I’ve contributed to, but… ok. Maybe it just maxes out at 4x.
That’s it, though, except for “Arctic Code Vault Contributor” which … is more chance than anything else.
( A guide for English speakers as of May, 2022)
I’m going to assume that this isn’t terrible if you speak a language which doesn’t look anything like English. I’m going to assume that your domain name registrar’s don’t have their heads up their butts.
Over here in the English speaking world they’re too anglocentric to notice anything that goes on in languages that have non-ascii characters. Since you’re reading this, you probably use a lot of software that was written by American companies. This means that even if you do succeed in buying an Internationalized Domain Name (IDN) there’s a very good chance that anything you try and stick it in that isn’t a browser will reject it. Especially if you try and use it for email.
org-roam supports multiple directories and it should work fine if you start that way, but if you’ve already got an org-roam project that you need to split up, it’s a pain in the butt.
Here’s how I managed to divide my org-roam project into multiple directories after much trial and error and googling.
A note before continuing: If you’re googling around for this you’re going to find a bunch of old commands from when people were upgrading from v1 to v2. Many of these won’t work because their names have been changed.
That sounds pretty obvious. It is pretty obvious. Anyone with any familiarity with older humans knows that they generally have trouble reading small text, or making out fine details. Every drug store has a rack of magnifying glasses. Everyone’s seen an older person doing the thing where they lift up their bifocals and start moving a thing closer and farther with their arm trying to find a spot where it both large enough to be readable but far away enough to be in focus. They’re not the only ones who need bigger text, of course, but they are the ones everyone should be familiar with, and likely has in their lives.
(Or, The Value of Working at Lower Levels of Abstraction.)
I’m loving working in Scheme because it forces me to work from First Principles.
There’s a huge value in the convenience functions that most languages wrap around those first principles, but it’s like buying and using a car vs. building the car you’re using.
The latter is more work but you’re going to really understand how that car works and you’re going to have the perfect car for your needs.
Emacs is arguably the most powerful tool available to the modern programmer. Vim’s pretty close. Both require more effort to learn than say Atom or Sublime Text. But, the additional start-up effort pays off quickly.
Like Scheme, they both suck out-of-the-box. Unaltered they’re both horrible bare-bones skeletons of an editor. Their potential is incredible though. If you’re just going to do something quickly, and never spend the time to customize them, they are a terrible choice.
When your data only exists in software that you don’t host yourself it is no longer yours. It can disappear at any moment. Its future is dependent upon a company’s continued profits and interests.
Imagine you’ve been building up a knowledge base for two years, but you fall on “hard times”. Maybe you can’t afford it. Maybe something happened and you’re literally unable to (accidents, medical issues, legal restrictions). What happens to all that data?
SSH Keys can be a little confusing to new developers. Here’s a quick little metaphor to help you think about how they work.
tldr; Your public key is your business card. You can give it to people so that they can add it to the list of people authorized to access a machine or service. Your private key is a tool that proves that you’re the person associated with that business card.
There was a recent post* about how Go is Google’s language, not ours. It was an opinionated post, but it provided some evidence to back up its claims.
Russ Cox (a Tech Lead for the Go language) posted a reasoned response to this which, I think basically tried to say that it wasn’t true, and they had regular meetings to discuss community proposals.
But for me, the telling bit of it was this:
I’m going tell you the tale of oho, a program which is arguably the world’s greatest ANSI text to HTML converter, and how it solved a real business problem. I’m sharing this because, as a geek, it’s important to remember that you can frequently solve work needs, while having fun creating open source tools that interest you.
Side note: ANSI escape sequences are the things that cause text to be colored, bolded, etc when displayed in a terimnal.
In 1981 Robert Cox came up with a slogan for Ford; “Quality is Job 1”.
It has always stuck with me.
In the software industry there are few slogans could be further from the truth. C-level’s and other customer facing types frequently proclaim the “quality” of their products, but they aren’t the ones making the product. They’re frequently not even the ones using the product.
In software there are two viable ways to release quality software. You can release it when everything you want done is done, or you can release what you happen to have done at a specific date. You can’t combine the two, although almost every software company tries to.
One of my coworkers was trying to understand the differences between libraries, frameworks, and DSLs and asked me
…how do I know what i’m using when all these things are
interacting and being used within each other, etc
To some degree, you don’t, and it doesn’t matter, but that’s not a very helpful answer. So let me step back and talk about what each of these are.
Libraries are the simplest. A library is just a collection of code intended to be reused. They’re typically packaged using a package manager, but it doesn’t need to be “packaged”. It could be just some file of useful code that you load into your code like any other source file.
I recently needed to convert some HTML to PDF on the command line and went hunting down the options.
There numerous posts saying “X is great” “Y works great for me” but no-one gives examples that show you anything.
I’ve tried WeasyPrint, wkhtmltopdf, Pandoc and Google Chrome (yes via the command line). The test was simple. Take a simple color chart, made from pre-formatted text and render it as a pdf. This doesn’t test any fancy CSS grid layout, or sizing or … anything. Just straight pre-formatted text with some spans that only define colors.
A high level summary (and paraphrasing) of Zed Shaw’s talk at DEFCON 15 (in 2007) because I couldn’t find a good text version.
Utu is the Maori word for a system of revenge used by Maori society to provide social controls and retribution. Utu is also a protocol that uses cryptographic models of social interaction to allow peers to vote on their dislike of other peer’s behavior. The goal of Utu is to experiment with the effects of bringing identity, reputation, and retribution to human communications on the Internet. A secondary goal is wiping out IRC because apparently nobody really likes IRC.
(or Why A Healthy Work-Life Balance Is Important)
During the dot com boom I worked at a company with a developer who loved his work. The problems were challenging, and we really valued the things he produced. Everyone who worked late late got dinner, and sometimes he’d work so late that he ended up sleeping by his desk. Bob (not his real name) wasn’t pushed to do this. He just really liked his job.
I’ve been thinking a lot about Scuttlebutt lately (see my Why Scuttlebutt post), and Srol just wrote a great post about how Mastodon makes the internet feel like home again.
There’s a lot of good reasons for people to use tools like them for socializing online, and I don’t want these services to just wither as their users wander off. I want there to be options that aren’t controlled by large companies, but at the same time services that require servers (like Mastodon) need someone to pay for those servers. And while Scuttlebutt doesn’t need servers, the “pub” servers do play an important role. I find myself wondering what is required for a social network to succeed? Are businesses a critical part of the equation?
v2.1
(Note: Manyverse / mobile users please see the warning at the end.)
Offically Scuttlebutt doesn’t support posting from the same identity on multiple computers (as of Dec 2017). Unofficially, it’s easy but requires a little bit of care. In practice this means never run the Scuttlebutt client on two computers at the same time.
The gotcha is that if you post from both computers before the changes of one have had a chance to replicate to the second via scuttlebutt one or both of your feeds will get screwed up and other people won’t see some of your own posts ever again.
Changelogs are an invaluable, and often neglected part of any software project. So, how do you do that?
A good changelog helps you users to understand:
A great changelog does all that, and shows the personality of your team.
Let’s start by taking it as a given that a Changelog file is something very valuable that every product should come with. Even if your “product” is a library for other developers.
With that in mind, the question rises of “How can I make it really easy to generate one”. Many developers have had exactly that thought. There are many free and some paid solutions that will “Autogenerate your changelog from your git commits/tickets”. The simple fact is, that no matter how well they’re written, you shouldn’t use any of them.
EDIT: As of Monterrey Apple has completely locked down the files you need to edit.
There are 2 ways I know of to do this, and neither of them is as good.
ĉ. You’ll probably have
to copy the character you want from here or any other page with it.
Then do the same for all the other characters that need ˆ. Here is
a public snippet group with the Esperanto Diacritics that I’ve put together. Just type cx to get ĉ, and so on for all the characters that use the ˆ or ˘ diacritics.ĉ. what it does, is exactly the same thing as Text Expander, only with +h or +x. Basically, what you get is an incredibly limited free version of Text Expander, that only works with the QWERTY keyboard layout.In short, buy Text Expander, because you’re going to get a ton of other cool functionality and it’ll work regardless of what keyboard layout you use.
There are lots of great tools out there. Far too many to try. Here are the ones that I’ve tried, and found worth recommending. Mostly they’re
Quiver is a “Programmer’s Notebook”. I’ve recently switched to it from CodeBox which seems to have been abandoned by its developer. I’ve got some minor quibbles with Quiver, but overall it’s pretty nice and I’ll be bringing all my code snippets and reference material over to it.
You’ve got a lot of software options when setting up a blog. Over the years. I’ve used or tried most of the options including, but not limited to: WordPress, Jekyll, Octopress, and at least 3 custom built systems.
What follows is my thinking on the pros and cons of each option, and why I’m switching back to a static blog system (Hugo this time).
Dynamic blogs, like WP, have a lot going for them:
In Programming Perl Larry Wall (in)famously suggested that programmers had three great virtues: Laziness, Impatience and Hubris. Over the years I’ve kept coming back to those because there’s a real truth to the idea as he originally presented it, but it’s limited, and his definition of “Hubris” has no relation to the actual word. I believe that those may be aspects of real programmers, a great programmer goes beyond that. Building on Larry’s idea, I present you The Five Virtues of a Great Programmer:
Vampire Bug: n. something that worked when you went to bed at 2AM, but when exposed to the light of the next day dies horribly. Typically the exposure proves that it couldn’t possibly have been working at 2AM either.
( as of Sept 30th 2014 )
These are the instructions for how to do it if you’ve already got it configured and need to add a new app / device. If you don’t have it set up already, GitHub’s docs are… probably passable.
This afternoon my intern asked me this simple question. She’s a new developer, and a friend of hers is working in a fresh codebase, with best practices. Everything is nice, and he can keep the entirety of it in his head. She’s working with my team, Support Engineering. We’re the front-line bug squashers at our company. We’ve got a legacy codebase with no tests and brain melting insanity around every bend.
First, it should be noted that not all stories are “User Stories”. For example a developer might be tasked with manually running some script. The Story might simply be “run the fooberry script”.
For everything that effects the UI, use a template:
As a < type of user >
I want < to perform some task >
So that < I can achieve some goal >
Note that it’s all about what the user wants. This isn’t about instructing what change to make to a system. It’s about advising implementers on what the desires of the user are.
Finding the Github pull request associated with a branch.
Work on a large enough project, with other people and sooner or later you’re going to find some commit, or branch, and want to know what was in the pull request that merged it in. Maybe you want to see what other commits got merged over at the same time. Maybe you want to see what the diff was at that point in time. But, how do you get from a branch name to a pull-request.
Writing code is a lot like maintaining a Bonsai Tree. If you stop pruning it it’ll stop being a Bonsai and turn into a bush. Little tweaks, frequently aesthetic ones, will help to keep it beautiful and under control. It will still grow in unexpected directions, as other developers make changes, but careful pruning will keep it balanced, and healthy.
What is “careful pruning” then?
Each file is a branch on our tree. The methods, are leaves. We come in to work and start examining one of the branches. Some days we need to encourage it to grow a specific way by adding a feature. Some days we make little snips to correct a bug. But what happens if, upon examining your branch for other reasons, you discover that it’s grown into spirals and knots. You can’t reach your clippers in to snip the leaves you need. You can’t do much of anything without difficulty and frustration, and frankly, it looks like crap. The unexpected spirals and knots need to go.
push is potentially very dangerous.git config --global push.default currentcurrent as your default behavior means no more complaints about setting upstream when pushing.When it comes to git push most people think “It pushes my current branch’s updates up to the remote server” but that’s only a small part of what’s happening, and ignorance about the rest can leave you with very upset coworkers. I know, because that’s exactly what happened to me today when I ran git push -f on a coworker’s computer that happened to have the default configuration.
This morning’s shower brought me an interesting series of thoughts that I thought you might appreciate, and it all started with the simple question of “How do you set The Atomic Clock?”
My first thought was that at some point you have to find some other clock and precisely sync up with it. Then again, they may have said “fuck it” and just had Bob press a button when some other clock flipped over, but then I wondered “How do we know what time it is in the first place?”
There are two things that make using vim awesome… no there are about 200,000 but most of them involve adding a few lines to your .vimrc to enable them, or installing a plugin. My .vimrc is just over 300 lines after all these years of use and customization. But, rather than go into all that, I figured some of the vim geeks out there might appreciate a pointer to some of the plugins I use. I’d also be happy to hear suggestions any alternatives to the ones I am running.
It’s generally good practice to rebase commits on a topic branch into a single commit before merging. It results in a much cleaner commit history, and makes rollbacks easier.
However, the question was raised: what happens if you…
push -f )The answer is based on understanding that a GitHub pull request has two forms of commenting: * comments on the pull request itself * comments on the commits that the pull request encapsulates. These are the comments made on specific lines in the diff.
Lets assume you’ve already cloned a remote repo and have been working with it. Now, someone has set up a second repo out there for the same codebase, and you’d like to interact with both.
*Please note: The following is based on the assumption that you have write privileges to the second repo, but don’t worry, you do essentially the same thing if you don’t and I’ll cover the differences at the end. *
A smart developer I respect recently asked my why I didn’t just register my domain names through my hosting provider. I hoped he was joking, that he knew why this was a horrible idea. He did not, and I know some other smart people who register domains with their hosting providers. Education is needed.
The problem is simple: conflict of interest. Should you ever decide to switch to a different hosting provider it’s in their best interest to prevent you from moving your domain. Why? Because if you point it to some other hosting provider you stop having to pay them.
Not too long ago I sent out a question. I asked people when, and why, dates were important to them on blog posts. The responses were revealing, both for what they did, and did not contain.
There are some situations where having a date on your blog posts is obviously needed. If you write about anything techy you absolutely need them. I come across tons of sites with perfectly good code examples, that have been obsolete for years. Ditto for how-to’s related to software and operating systems. The other place where dates are critical is anything related to news or politics.
I’d like to make a simple offer to the web geeks out there:
One hour of one person’s skills, to make the web a little bit more awesome, and raise $75 for your favorite environmental or medical charity.
Information Architects (the people behind iAWriter) have come up with a really spectacular JavaScript / CSS widget. When you load one of their long articles (like this one) you’ll see a widget in the top right corner that says “Older | Newer” and links you to the previous or next article. No big deal. What’s cool, is that as you gradually scroll through the article the widget disappears, then returns, hovering beside your scroll bubble (wherever that may be in its track); its message now telling you how many minutes it’ll take you to finish the article, at an average reading speed. When you get to the bottom it reverts back to the “Older | Newer” state.
I’ve just merged the experimental branch of MObtvse into master. This represents a huge update and in addition to the feature list below there’s a nice update to the default theme, great new editor, improved Kudos integration on the admin screen, and a number of more subtle improvements. I’m really happy with the progress I’ve been able to make on MObtvse in my free time, and if you’ve been considering it, now is definitely the time to grab it from Github and give it a spin.
I think Dustin Kurtis’ idea of “Kudos” is spectacular. A simple tool for people viewing your post to say “I really appreciated this.” You can see it in action in the upper-right corner of every blog post in the Svbtle blogging network.
I really want to bring it to MObtvse, but first I had to figure out how it worked. So, I’ve put together an example implementation of Svbtle-style Kudos that can be incorporated into your blogging software with a few easy changes.
Today, I would like to introduce you to MObtvse. It’s a fork of Nate Wienert’s Obtvse, a Markdown based blogging system written with Ruby on Rails. Obtvse is itself, a reverse engineering of the Svbtle blogging platform / network.
The notable differences between MObtvse and Obtvse are that:
MObtvse doesn’t currently generate static pages, but support for statically generated pages is a top priority. The faster serving helps SEO and allows a single server to handle far greater numbers of readers.
…to crush your enemies and/or bugs
Or, how to save countless hours and find out where things broke
Git bisect is the most awesome, and most poorly publicized feature of git. It allows git to walk through your branch and quickly find out which commit broke things.
The usage is simple. You point git to a bad commit ( usually the most recent one ) and you point it to a good commit (the most recent one you know of when things were working). So, if, for example, things were working on Tuesday morning, you bring up git log and scroll until you find one from Tuesday morning or maybe late Monday and copy its hash.
There are many ways to get specific files from another git branch into your current git branch (overwriting the ones in your current branch), but this is the only method I’ve been able to find to merge those files into your branch en-masse. With this method you’ll be able to pull in any file, or files based on the name of the file or containing folder. If you need to merge files in multiple folders on different subdirectories you can simply rerun step two with a pattern that matches each of the different portions of your tree that you wish to merge.
You can tell weather or not someone really “gets” unit testing by asking them one simple question, “Do you use mock objects?” Almost invariably, they will say “no”. Even people who have totally gotten the testing religion. It’s like watching someone pray to a statue of Jesus; totally oblivious to the fact that Jesus himself is standing four feet away reading a book.
This is partially due to the fact that most geeks don’t actually know what a unit test is. They think that testing the methods of a specific class constitutes a unit test, but that’s only part of the story. A unit test test is when you test the methods of a specific class in isolation, and the difference is critical. You know how some people call us “computer scientists”. Yeah, well this is the science part.
I interview a fair number of geeks every year and usually spend my alotted time going over one programming challenge. Lately I’ve been looking for a new one that was simple, but still big enough to give me a glimpse into their thinking. I think I’ve found it.
I really like this question because:
You’re presented with the following YAML file which you need to convert to a useful data structure, but for whatever reason you don’t have a YAML library. You do however, have something that has converted it into a tree of nodes.
There are two good reasons to serve Octopress from a self-hosted git repo.
Complicating factors:
These instructions are not for people uncomfortable with using the command line in a *nix environment. Of course, if you were uncomfortable with that you probably wouldn’t be using Octopress in the first place.
This is a simple idea for every web development company (small or large) that owes its existence to open source software. I’m going to use Ruby on Rails as an example, but this is just as applicable to all of the other frameworks and tools we use daily.
On the first Wednesday of every month all of your developers work on bugs or needed features in one of the frameworks or tools that your company can’t live without.
Where you spend your time developing is an important decision for an open source developer. Partly we do it for personal satisfaction, partly we do it to give us a tool we want, but there’s always a part of us that wants others to use and enjoy our work. I want to talk about that, and I want to talk about the frustrations that people who use those open source projects have, but first I need to set the stage. Paul Ruoget (@paulrouget) has been working on a cool live CSS editor for Firefox which should be out in FF 11.
The idea is that it can be very useful to base64 encode an image directly into your css file instead of referencing a separate file, but doing so usually involves dropping to the command line, calling openssl, copy-pasting the output, specifying the mime-type, etc… Bret’s Terpstra distilled all of that into one drag-and-drop command for Textmate.The following is simply a generalization and instructions for using the drag and drop in MacVim / GVim
There are a few problems with Jekyll / Octopress though that would, realistically, make me less inclined to use it. First, you need to have your entire blog checked out on whatever box you’re posting from, and that is simply not something I’m willing to do on a work computer, and not something I necessarily can do when on a borrowed computer. Secondly, the user interface sucks. Well, there really isn’t one.
The other day the Googlebot swung by to check my site for updates and found Malware. Almost immediately, it seemed, people’s browsers were warning them off from my sites. Malware! Bad Things (TM)! There be Dragons here! and so on. Fortunately a friend dropped me a Tweet shortly after it started and thus the hunt began with one clue:
Malicious software is hosted on 1 domain(s), including globalpoweringgathering.com/.
Sadly, that was ALL I had to go on, and when I told the browser I was ok with the risk (Windows malware can’t hurt us Mac folks) I was unable to find any calls to JavaScript to files on my blog. I couldn’t find any that were encoded either. I was stumped. Poking around on masukomi.org, which is just plain HTML files I did find they had all been prepended with an evil script tag, but that was easy enough to replace as there were only a few files. weblog.masukomi.org though… I was stumped. I’m still not sure where exactly it was coming through to the browser, but I did find the culprit.
It’s a big back-and-forth between developers, with lots of us swearing by the use of spaces, but I’m here to explain to you why everyone who uses spaces instead of tabs for indentation is not only wrong but seriously inconsiderate of their fellow developer.
First though, we must consider what a tab is and what a space character is. A tab is a typographical element specifically designed for the indentation of text to various levels. A space is a typographical element specifically designed to separate individual characters so as to distinguish words from each other.
Every week I, and millions of developers like me, have to put together a status report for our bosses, letting them know what we’ve been up to for the previous week. Like most of the developers I’ve encountered I’m always a little unsure of what *exactly* I was working on, and typically I just open up git to see what commits I made, and try to remember any non-code stuff I’ve Thinking it was silly to keep wading through everyone’s commits for the past week to see what I worked on I’ve put it all together in a script (in Ruby) called git status-report, which you can grab from github here.
Rebase is one of the most powerful tools in Git’s arsenal, but it can trip up people coming from centralized version control systems. This is just a quick example of why, and when, you’d want to use it.
Let’s say we’ve got a team of three developers. Monday morning they all come in, Bob makes a quick commit, and shares it with everyone. They all do a git pull and suck it into their repos.
Every web page on the internet has an URL that is a unique address (that’s why it goes in the “address” bar), and in the beginning everyone used that. But early e-mail clients kinda sucked, and some of the current ones still do, and those addresses were so long they’d wrap, or had some funky characters in them that the e-mail client wasn’t expecting, and so it’d break the URL in such a way that you’d have to copy and paste both parts of it into the address bar instead of just clicking on it.
Because it took me freaking forever to find instructions on how to do this…
You do NOT need a message-resource tag in your struts configuration files. Those are outdated instructions for old versions of Struts.You do not need to edit ANY xml at all.
Your Action needs to implement Freemarker’s TemplateMethodModel interface
You need a package.properties file (the default locale) and a then another one for each other locale / language you want to support (ex. package_en_US.properties). These should be located in the same package as the Struts action that will be needing them. You can also do ClassName.properties if you want to tie some to a particular class.
First, let me explain what I mean by “tiered password scheme”. Many perfectly smart people I know have one strong password they use for one or two online banking type sites. They’ll then have a “medium security” password they use on sites that kind of important to them (maybe those sites have their credit card info stored), but not critical to day to day stuff. Then they’ll have one or two passwords they use on all the other sites like Twitter, Yahoo!, Facebook, GMail, etc.
It’s not uncommon for me to wonder if some app is running on my linux or OS X box, and while I could pipe together ps and a couple greps it felt silly to keep doing it after a while. So, I applied my admittedly limited bash skills and came up with the following script which I throw that in an executable called “got”. Now I can just type “got tomcat?” (the question-mark is optional). If anything is running with “tomcat” in it’s command it’ll give me the skinny on it. Otherwise it’ll let me know it wasn’t found.
If you’re like me you find yourself sitting at your computer and need to go away, but there’s some page you’d like to read, or continue reading, on your phone. Well, if you’ve got an Android Phone or essentially any phone in Japan you can just use your phone to scan in a QR Barcode from your computer screen and then open the url on your phone. I know for a fact that there are other phones in the US that can read QR Code, but you’ll have to Google around to see if your phone is one of them. Sound good? Then go here, see the screenshots, grab the bookmarklet, and let me know what you think. P.S. If you’re interested in seeing what’s going on with 2D barcodes as we start to catch up to Japan you might be interested in checking out the 2d code news site.
Developershare: adj. The percentage or proportion of the total available pool of developers that is coding for a particular product or platform.
Example: Regardless of how good the Palm Pre is, Palm will be hard-pressed to steal any of iPhone’s developershare.
Yesterday I was discussing the fact that I need a new laptop and how much I wanted to get an HP Mini 1000 (cheap, ultra light, good manufacturer), but couldn’t because of those damn independent Mac developers. They keep making incredible apps I simply won’t give up. Unsurprisingly, he asked me what my killer apps were for the Mac, and I thought you might be interested too. But, before I start the list, I just have to give a major shout-out to the indie developers for OS X. You guys make the most creative, useful, and beautiful software on any platform. If it weren’t for you I would have given up my Mac years ago.
I love programming. I really do. It’s one of the few things that really gets my brain buzzing. In my twenties I’d go to work, program my ass off, then come home and repeat. Or, when I worked for myself, I’d just not stop. But, as I make my way through my thirties I’ve found that most days I come home and simply don’t want to look at code anymore.
John Kelvie said:
[To] me the fundamental challenge with existing version control systems is the difficulty of merging change sets from multiple developers across the same set of code. To me, this issue comes down to the diffing/merging functionality provided by the software, and I haven’t seen or heard of anything that really improves the state of the art. How does GIT address this? How does it make it easier to do? Are there specific branching and merging tools it provides? Is through the use of more atomic commits (which I could see helping to an extent, but only so far as it allows for changes to be small enough that there is no overlap, thus sidestepping the problem).
If you’ve ever:
…then distributed version control is worth your consideration.
typelation: n. The act of converting speech, or thoughts, into text for a text-based conversation (e-mail, instant messages, etc.). Example: The joke lost something in the typelation.
Angle-bracket Operator: n. A person who manipulates HTML professionally. Also see Web-designer.
General Patton said that “A good plan violently executed now is better than a perfect plan executed next week.” If he was a coder he might have said “An automated test violently executed now is better than a perfect test next week.”
If your Test Case is a package whose goal is to test all aspects of a particular class then a Test Suite is something which kicks off a collection of related Test Cases. As with most things in Perl’s Test::Unit it’s really easy to do and also terribly documented. So, without further ado… You need something to kick off all your tests:
use Test::Unit::HarnessUnit;
use My::Test::Suite::Package;
my $testrunner = Test::Unit::HarnessUnit->new();
$testrunner->start("My::Test::Suite::Package");
Next you need the test suite it’s going to kick off:
Pretty much everyone agrees that Gravatar rocks. A global avatar that shows up wherever you make a comment on a blog (sometimes even in your desktop apps). And I don’t think anyone other than naive VC guys wants another “social networking” site, so I’m not going there. But, imagine what would happen if every time you made a comment on a blog that used Gravatars a ping was sent off to the “Gravanetric” servers with two bits of information the hash of your e-mail and the root url of the site you posted too.
Sometimes you just want to distribute the source code without its history, and that’s where git-archive comes in. git-archive will create an archive of the files at any point in the history and wrap them all up for you in a tar or zip (defaults to tar). You can even make an archive from a remote repo by using the
—remote=<repo>
option in the administrator has enabled it.
You’ll typically use git-archive like this:
I’m reading through Squeak By Example because I’ve got some ideas rumbling around in my head that might be nice to do in Smalltalk. Having an integrated visual environment where everything is an object opens a lot of data visualization possibilities. Anyway, it has been probably two years since I’ve touched Smalltalk, and even then it was pretty brief. So I needed a refresher course.
I’ve been flipping through it looking for random bits of information I was interested in and found them all. Then, I went back and started from the beginning, following all the instructions, doing all the examples…. They’ve done a great job explaining things, it’s really easy to follow, and gives you an excellent step-by-step introduction to Squeak’s IDE, and that’s a very good thing if you’re not familiar with Smalltalk.
 The same friend who wondered about how to share a Git repo over
HTTP dared to suggest that “It’s so easy with Hg…”. While I happen to
disagree that it’s easier in Hg
than Git, I think this flow chart successfully
demonstrates that, on this front, Hg and Git both suck ass when compared
to Darcs.
The same friend who wondered about how to share a Git repo over
HTTP dared to suggest that “It’s so easy with Hg…”. While I happen to
disagree that it’s easier in Hg
than Git, I think this flow chart successfully
demonstrates that, on this front, Hg and Git both suck ass when compared
to Darcs.
P.S. Yes, while 100% factual, the graph is also intentionally silly.
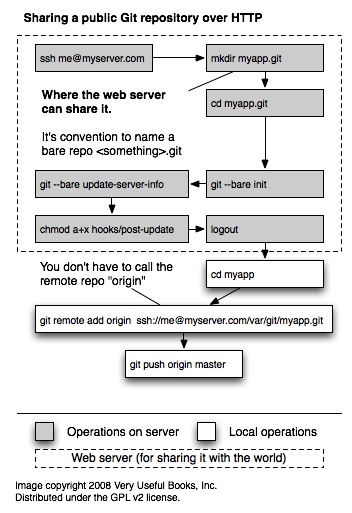
There is also an SVG version of this flow, which is more readable (but poor IE folks will have issues). Notes: This is a simplest possible configuration. Be sure to check out the docs for git-remote to see how to, optionally, designate specific local or remote branches. Many of the initial commands could be performed locally and then just uploaded to the server. This particular sequence guarantees that all the connection pieces are in place and working correctly.
Sivaram said: “I have been using CVS on and off for a long time; so using git is a bit confusing.
If all the repo clones are equivalent, how does one know one is the ‘clean’ repo? On CVS, there is a centralized repo lying somewhere. I can’t seem to wrap my head around the decentralized model.”
This question trips up a lot of people when they’re introduced to the concept of distributed version control systems. But the answer is exactly the same as in the centralized world. It is wherever the project maintainers tell you it is. Let me give you an example:

A simple flow chart showing the steps you should take to add an existing codebase to Git. This assumes you don’t have revision history that you wish to migrate from another version control system. Some notes about the flow:
This image is copyright 2008 Very Useful Books, Inc. and distributed under the GPL v2. It was created With OmniGraffle 4. If anyone wants the original, just holler.
First, let me set the stage. I’ve been reading stumbling across
interesting data information articles by Edward Tufte for years now, have
been interested in getting his books
The first two thirds were not bad. The second two thirds sucked. The type of people who would appreciate this course the most are ones akin to the woman in front of me who wore red velvet pants, a scarf that probably cost $60 and from the Museum of Fine arts, dangly earrings of semi-precious stones, and, were you to talk to her, would be sure to let you know that she’s “an artist.” She loved it. You, on the other hand, should buy his books and skip the course.
Not too long ago I decided to start writing a book about distributed version control. I was originally going to focus on Mercurial (Hg) because it’s quite good and of the two leading systems it was the only one that ran on every OS (because it was written in Python). The fact that it could also run under Windows meant that I could help spread the word about distributed version control to more people, and it slightly increased the chance that I might actually make some money in the process.
Piers Cawley just posted about Martin Fowler’s attempt to write a book about DSL’s actually, “internal DSLs”. Piers calls these “Pidgins” and I think it’s a pretty good term for them.
These are the sorts of languages where you don’t write a lexer or parser but instead build a family of objects, methods, functions or whatever other bits and pieces your host language provides in order to create a part of your program that, while it is directly interpreted by the host language, feels like it’s written in some new dialect. - Piers Cawley
[EDIT] Odiogo is now some sort of Japanese Car site. As such, this page has been obsoleted by yet another cool proprietary product disappearing.
Odiogo will take your blog’s rss feed and run it through a text-to-speech converter so that people can subscribe to it as a podcast. It’ll, obviously, have the same quirks as any other text-to-speech converter and is, probably, limited to English but it’s a pretty nifty idea, even if their name is a total rip-off (Odiogo makes rss into podcasts Odeo manages rss feeds of podcasts). Also, they seem to have done a really good job with the intonation of the computer voice.
_why suggested that
…chaos is an essential component of writing code. The system is too big for you to fathom. So you are always finding yourself in unfamiliar territory. And once you fathom the system, it becomes too boring and tedious to pay attention to details…
…Unit testing, in particular, is designed to reel in spontaneous hacking. It is like framing a picture before it has been painted. Hacking, at heart, will continue to be something of spontaneous order, something of anarchy, and the landscape of hacking is something which comes from human action but is not of human design.
The other day I posted a rant about “Alphabetical != ASCIIbetical”, which, much to my surprise, got picked up in a couple places and brought thousands of readers. As with any post that gets thousands of readers, some of them are going to call you an idiot.
…I don’t know what you call this sorting order, but it most definitely is not alphabetical. Maybe you should make sure you aren’t being a dumbass before you climb atop your own soapbox of delusional self-importance. - Dave G.
[BEGIN RANT]
Partially this is a case of Java community being populated by idiots, but people seem to be wholly ignorant on this issue in other languages too. Google for java alphabetical sorting capitalization or any combination of words you can think of that might get you an algorithm that sorts a collection alphabetically. You will find hundreds of wrong responses and no correct ones. Most of them say to use the Arrays.sort(..) or Collections.sort(..) methods. But both of those use natural order (or ASCIIbetical as I like to call it) not alphabetical order so 1 is followed by 10 not 2 and things starting with a capital letter aren’t beside things with the lowercase version of the same letter.
Some of you may be interested to know that SSCM v 0.4 has been released. Notable changes: supports move operations, fixed a bug with perforce support, allows you to live dangerously and just accept all detected changes into the repo without asking.
The two things I’d like to get in there now are branching and merging all the known repos with one command each. Should be relatively trivial for the distributed clients, but the centralized ones will be a little work. Anyone feel like pitching in?
Testing as a process of discovery
The other day a coworker said,
Some times you get situations where the specification for the unit or module you are writing just are not available. The code writing is a discovery process as much as anything else. Moreover, some of the packages and methods being called don’t have predictable or documented behavior. That’s ugly and horrible, and I don’t know how that’s allowed, but nonetheless, from the perspective of someone who wants to do unit testing in such an environment, can you give any tips? I mean, do you mock up approximations to what you think these external things should be doing if you really don’t know what they are doing? Do you do your best, updating mocks and tests, “in the face of adversity”?
This projects has been rolling around in my brain for a while but I haven’t tackled it yet because I have too damn many other projects in process. So I’m putting it here in the hopes that maybe someone will pick it up and run with it.
I want to put together a collection of javascript based graphing tools that generate pretty SVG graphs of your data in a way that’s fun to look at for people who have to work with it every day but not necessarily something you’d ever want to try and explain to a customer. I want to do this because we deal with a crapload of really interesting data at work, but a lot of it is just internal and only of interest to geeks. Also I’d like a visually interesting way to keep an eye on the status of our systems and the data flowing through them. Stacked bar charts and line graphs get old fast.
Is it testable?
Apparently some people are having trouble with determining if the code they’ve written is testable. So I’ve put together this flow chart to help you navigate through this complex decision making process. The image is distributed under the WTFPL license so please feel free to use wherever and however you want.

Yesterday’s flow chart was designed to help with the complex issue of determining if a particular piece of code is testable. Today’s flow chart helps with the equally complex problem of determining when to write, or run, your tests. Like the last one it is distributed under the WTFPL license so please feel free to use wherever and however you want.

I just put together a new unit testing presentation for the folks at work and you. Although it may need to be edited here and there for your coworkers… maybe mine too….
Anyway, Unit Testing 101 (v2) requires Firefox and I recommend you move your mouse up to the top edge and click on the icon to the left of the slider where you’ll get a menu of all the chapters and slides. Yes, there are a lot of slides, but it’s Takahashi method so they go really fast.
The best thing about Distributed Source Control Managers ( IMNSHO ) is how quick and easy it is to branch and merge. The problem is that most of us cut our teeth on centralized systems that couldn’t even hope to take advantage of cherry picking, which is, in short the ability to take a single patch out of the middle of a sequence of patches, or every patch but one from a sequence. Just imagine knowing that there was a bug introduced in a specific patch and being able to prune it from your repository but not any of the patches around it. Or, plucking one little feature out of a mass of others that should wait until the next release. You can, but if you don’t make the effort to keep your patches as atomic as possible you’ll find that that patch you want to remove or extract is dependant upon another one, or more, that you may not want to involve.
Lloyds of London is able to do what they do thanks to the concept of underwriters. The simplistic version is that a risk is spread amongst a group of underwriters. If nothing goes wrong they get a cut of the profits relative the the percentage of the risk they took on. If things go wrong they take pay for whatever portion of the risk they agreed to take on.
For any given programmer the following statement should always be treated as truth:
My code sucks, but your code sucks more - Dave Astels [deleted post]
Good version control habits and test coverage will get you out of most jams related to your own code but we rarely write apps that are comprised of just our code. There are almost always libraries from other people code that you’ll include to save yourself from having to re-invent the wheel. Obviously you don’t want to start writing unit tests for code from other projects (you’d never finish) but there are some basic steps you can take to minimize your chances of failure.\
99 lines of code on the wall.
99 lines of code.
You look around, refactor it down…
98 lines of code on the wall.
98 lines of code on the wall.
98 lines of code.
You look around, refactor it down…
97 lines of code on the wall.
Or, alternately
function singVerse(numLines){
if (numLines \> 0){
document.write("" + numLines + " lines of code on the wall.\\n");
document.write("" + numLines + " lines of code.\\n");
document.write("You look around, refactor it down...\\n");
numLines -= 1;
document.write("" + numLines + " lines of code on the wall.\\n");
singVerse(numLines);
} else if (numLines == 0) {
document.write("Totally bug free code on the wall\\n");
} else {
document.write("Need more tests for the code on the wall.\\n");
}
}
singVerse(99);
I keep thinking back to a short comment at BarCamp Manchester in the Unit Testing talk. When asked if anyone had written an app with 100% code coverage the guy beside me raised his hand. Now I’ve been advocating for a while now that it’s essentially wasted time to bother testing your getters and setters, and when I mentioned something to this effect he said, “How do you know you haven’t made a typo in a variable name?”
Justin Jamesasks why nobody seems to care about performance anymore. He talks about how the performance hit you get from using a “slow” language directly translate into increased hardware and electricity costs just to maintain the same kind of performance you would have had if you’d used a “fast” language or spent more time optimizing your code.
All his points are good, but they’re also all irrelevant. You see, for most applications the performance hits you get from slow languages or non-optimized code just don’t matter. Your system will still be responsive enough that no-one will be bothered. People don’t care because it just doesn’t have any noticeable effect on the end product and some languages make coding far more enjoyable and productive. Their productivity gains far outweigh performance hits that are almost unnoticeable by end users.
I’ve been programming in Java professionally for years now, and while I’ve become good at it, it’s never grown into a language I’ve been passionate about. It’s powerful, has tons of good libraries and tools but… It’s like going out on a nice date with someone but having no desire to ask them out for a second. You wouldn’t mind another dinner with them, and since you’ve got a common circle of friends you probably will, but you’re never going to get the butterflies in the tummy when you think about seeing them again. I’ve met a lot of people who’ve been out on a date with Java, and so far none of them seem to have tummy butterflies either.
A reader commented that
…the syntax of Perl is so hideous and mysterious it produces unmaintainable code (I know having maintained a multi-tier Perl webapp).
And, sadly, he’s not the only one that shares that belief. Perl has been written off by many talented developers because essentially every piece of Perl code they’ve ever encountered is, well, crap. But, when you get right down to it you’re basing your opinion of a language based on what people write with it. It’s like saying that the English language sucks because there are so many vile and crappy things written in it.
O’Reilly has just agreed to assign
…the full copyright in the book “Perl 6 and Parrot Essentials” to The Perl Foundation. The text is out-of-date, but can be updated much more rapidly than it can be rewritten from scratch.
Three cheers for O’Reilly. I wish more publishers would stop being so damn stupid when it comes to the copyright on old books that they have no intention of reprinting. Especially geek books which are frequently outdated and no-one would want them if they were reprinted (not rewritten).
Have you noticed? Geeks don’t touch. I noticed this in myself a while ago, and have since been watching other geeks to confirm my theory. I was at the Boston Ruby User’s Group a week ago and essentially no-one touched. When two geeks are introduced, unless it’s a somewhat formal introduction like an interview, we don’t shake. When we encounter each other, or go our separate ways, there’s no casual touching. Many will actually wave at each other in greeting from a few feet apart so as to avoid the simple touch that normal people would expect. I think this is a byproduct of the fact that so many developers are autistic regardless of if they realize it or not.
If you’re reading this blog there’s a fair chance you’re a programmer and that means that from time to time you’ll encounter people who want advice on leaning how to program. Unfortunately, it’s hard to point them in the right direction because we generally don’t want to spend the time to teach them ourselves and even if we did most of the learning to program books just plain suck.
So, I’d like to recommend two books. The first is Learn to Program by Chris Pine.This is the best intro to programming that I’ve ever seen. It’s not concerned so much with how to do things in a specific language as it is with teaching people the basic principles of programming although it uses Ruby to do so. It’s based on a series of tutorials that are still online but have been improved on, and expanded upon greatly in the book.
I just read an article that compared the crowd management techniques used in the stadium in ancient Pompeii to modern techniques, and while it’s an interesting read all by itself, and I do recommend you read it, I got to wondering about how similar ideas would apply to software design.
He’s actually talking about the bathrooms and concession stands but there are a couple applicable bits here: The bathrooms are an incredibly important part of any stadium. They also have nothing to do with the core purpose of a stadium. Keith recommends three things in regards to their creation:
It’s so obvious you have to wonder why people haven’t been doing this for years now…
Witten proposes an incredibly simple and good way to evaluate a potential employee’s code skills during the interview. Instead of asking arbitrary code questions ask them to send in a code example they’re proud of before they come in and actually go over that code with them during the interview.
This is a much more realistic test for exhibiting coding prowess than some sort of artificial string manipulation problem. Additionally, and this is a hugely important point when performing any interview, it tends to put the candidate at ease to talk about their very own pre-written code, so they’re not sweating bullets and thereby giving you an inaccurate reading.
I think I understand why people tend to not write tests. Because they
believe that tests aren’t something that’s either needed or important.
“Duh,” I hear you say, but bear with me.
Why don’t people believe that tests are something that’s either needed
or important? Well, I think one of the biggest contributing factors to
WHY is that essentially zero of the learn to program in language FOO
books ever mention unit testing. Unit testing has been around in a
formal sense since the creation of SUnit back in
1994
! 1994 I say! That’s thirteen years now. Thirteen years and I could
probably count on one hand the number of introductory language, or
language reference, books that not only mention unit tests but actually
explain why their important and how to use them. Even worse, most
languages don’t have unit tests tools built into their core libraries.
All the modern languages have fairly comprehensive test coverage but
they have to use external tools to write those tests. How crazy is that?
We have this common programming task that we all agree is critical to
releasing a stable version of the language but it’s not important enough
to build into the language. Wha?!?! The end result is that since we
don’t teach tests as being even noteworthy when teaching a language
no-one learns that they are important. For the most part people just
don’t seem to understand the value of tests until they’ve been in the
industry so long that their feet are riddled with holes.[1]
Mike Clark, and others, suggest [writing “Learning
Tests”](http://clarkware.com/cgi/blosxom/2005/03/18#RLT1 “writing “Learning Tests””)
as a way, not only to learn a new language, but as a way to accrete a
repository of what you’ve learned about a language. I think this is a
GREAT idea. Imagine if every book that taught a new programming language
showed you not only how to do something but then followed it up with how
to confirm that you didn’t screw it up by demonstrating how to write a
test for it? People would start to see test writing as a standard part
of the software writing process. It would be “just what you do.”
Imagine the impact that including unit testing as a standard part of
the learning process would have on the software industry! Sure it might
take five to ten years before we started to see the results from it but
wouldn’t it be worth the wait?
[1] From having shot themselves in the foot on many prior occasions.\
If you look at Mingle, the project management tool we’ve been working on… On that tool I happen to know that their test base is twice as much as their code base. So, two-thirds of the code in that product is tests, and that allows them to do quite violent things. I know that a couple of months ago they made a very fundamental change to the database scheme. I mean, we’re talking, utterly to the guts of the database scheme. And they did that and… it wasn’t even an event worth talking about. And, when they were planning to do it they were saying ‘Yeah, yeah, we’ve got to fundamentally alter the core tables in this application… Yeah we’ll do that, and it’s not a big deal.’" -Martin Fowler (paraphrased)
The software development industry is plagued with bad practices even though so many of us know better. A HUGE portion of this problem is that to really start, and continue, working the way we know we should requires buy-in from our managers and coworkers. And it’s not just a conceptual buy in that we need. People need to really get the religion. But, you and I both know that we can’t realistically expect the rest of the company to change everything at once.
Most web developers will agree that unit tests are great, and some even write them…but I know very few developers who write unit tests for their JavaScript, but it’s not really their fault. Most don’t know of good unit test systems for JavaScript and / or don’t write their JavaScript in such a way that you even could test well. This means breaking all the functionality into discreet functions and objects instead of writing old-school procedural crap. There’s also the obvious problem that most of your JavaScript is tied to the browser and the current page. So how do you test stuff in the page? Well, JsUnit lets you do just that and, seeing as I’ve just added a javascript implementation to the FizzBuzz Overthink you can run over and see how to do it for your apps too.
Another graph for another friend who asked for a flow chart of the
branching and merging described in Best Practices for Web Development
html
pdf.
Update:
Michael says: I’m a little unsure, from you diagram, how, if your trunk contains two completed and merged features that aren’t yet live (video upload and REST API, say) you put one feature live without putting the other live. It looks like code only gets to the live branch via the trunk, but it seems from your diagram that the trunk could contain all manner of complete and semi-complete features.
A flow chart for a friend demonstrating, step by step, how you’d go about using Darcs (or any other distributed version control system) with SVN / CVS. He needs to do it for the most common reasons:
Click on the image to get a full sized version. Or download the dia file here.
UPDATE: I’ve created a new subdomain for the FizzBuzz Overthink project ( http://fbo.masukomi.org ), updated the links below to reference it instead and modified the Readme in the project (and the default page of the site) to reflect the new goals of the project
UPDATE 2: There’s a JavaScript example in there now too which, of course, includes unit testing. More details here.
I was talking with someone the other day who mentioned, in passing, how they wished they had some good examples of how to do unit tests for his co-workers. There are, of course, plenty of examples of how to do unit tests but I haven’t seen many online that show them in the context of a complete but simple application. This conversation made me remember my FizzBuzz Overthink (FBO) that I’d written in Java, and it occoured to me that it would make a great teaching application. Translating an existing FBO into a language you’re trying to learn is also a great way to get your head around it.
This flow chart will only make superficial sense unless you’ve read the Triage section of my Best Practices for Web Developers essay, which I happen to have just updated with an expanded Triage section.
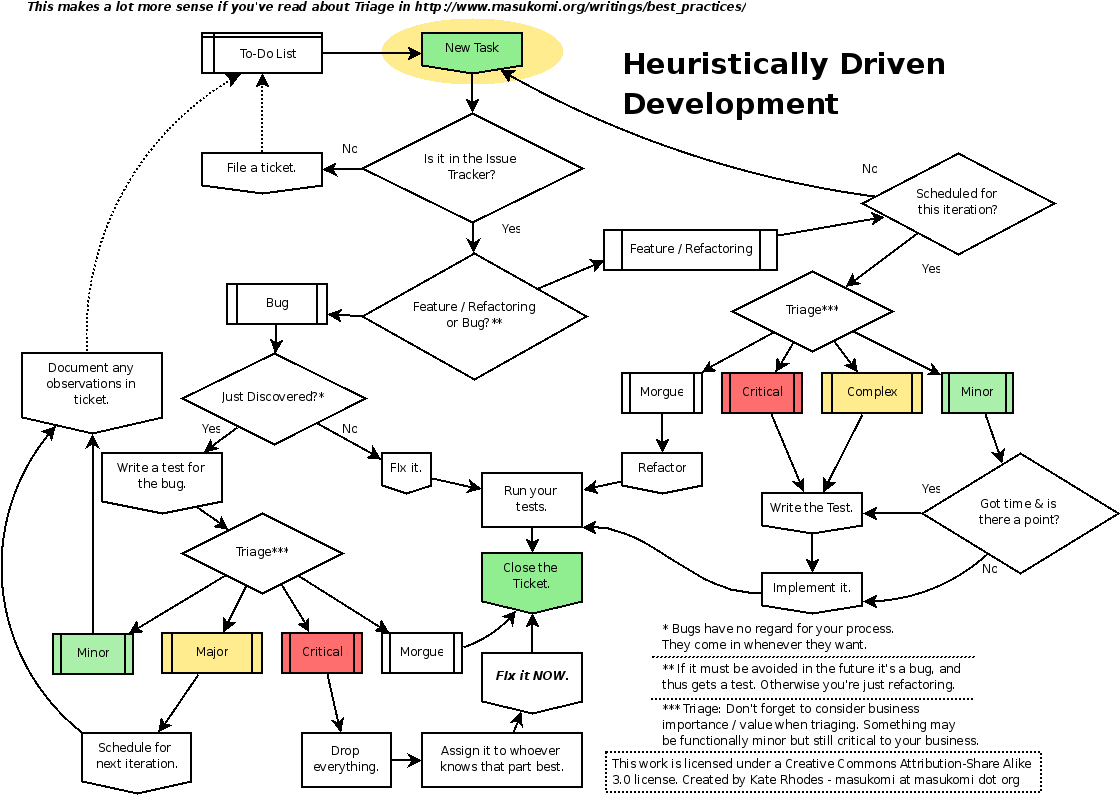
Click on the thumbnail for the full-sized verison. If you’d like, the Dia file is also available if you feel like tweaking it.
For the most part web developers spend our time guessing what features people might want and how said features should be integrated. Frequently we guess wrong and that wastes time and sometimes frustrates users. But there are tons of users out there who also happen to be developers and they’re actively implementing new features for their favorite sites with Greasemonkey. UserScripts.org has over 6,000 scripts. That’s 6,000 features with working implementations for popular sites at no cost to those sites! Free I say.
If you build this I will buy it.: Ergonomic Dvorak keyboards are effing expensive. Dvorak keyboards are hard to find in general and software remapping in the OS has a variety of…. issues. I want a USB dongle that remaps keystrokes from a QWERTY keyboard to Dvorak. Even better put a switch on it to turn off the remapping. I will pay up to $25 for such a device.
Currently web frameworks are all about the page. This is starting to change a little thanks to Ajax but mostly just towards the idea of page snippets. But why? “Pages” are a metaphor taken from books, but books are linear and the page serves to restrict the layout. Things like Yahoo Widgets have shown us that there’s no need for layout to be bound to the “page” metaphor and we’ve known for a long time now that webapps are rarely linear, and when they are people don’t like it. Essentially we’re writing glorified “choose your own adventure” games that still say “To open the door on the left go to page 65. To open the door on the right go to page 27. Rails, and it’s clones, even number the “Pages” like that. We need a new metaphor. What if, instead of writing frameworks that are all about serving and managing pages, we started to think of webapps more like pinball machines. There are 5 major parts in every modern pinball machine (other than the ball):
Some of you have gotten the distributed version control religion (If you haven’t, you should read my Best Practices essay) but are stuck with Subversion (or CVS) either because that’s what they use at work or because some part of your deployment systems use it. You may also want to combine them simply because of the power of svn externals which lets you pull in some of your code from constantly updated , Subversion Based, 3rd party repositories. Using SVN with a distributed version control system also gets you a cannonical, no doubt about it, central repo, instead of just a repo that everyone agrees to call the central one, plus you can utilize all those nifty notification and stats tools people have written for svn.
I wrote this essay a while ago and have been tweaking it based on the feedback from those I’ve sent it to (thanks guys). There are a few things I’d like to change still but I’m going to go with the “Release early. Release often” mantra on this one. I think it’s more important that it get out there than it being perfect.
Best Practices for Web Developers introduces the idea of Heuristically Driven Development ( HDD ) as it applies to web development, but honestly almost everything in there is applicable to all forms of development. There’s an HTML version and a PDF version and your feedback would be greatly appreciated and help to make the next iteration of the document better.
Raganwald suggests, with good reasons, why you shouldn’t over-think FizzBuzz. Obviously I took a different view of it and yet I still agree with all of his points.
So, I’d like to counter with some reasons why you should over-think FizzBuzz, and why I did, because I don’t think I did a great job of explaining that in my last post. But first, lets assume you’re not being asked to solve it on a whiteboard while the interviewer waits. In that case my 400(ish) line solution is completely inappropriate. In fact, anything but a quicky solution is inappropriate. Lets also assume that in submitting an over-thought solution to FizzBuzz you make it perfectly clear that you know it’s over-thought and what you were hoping to achieve by going to such ridiculous lengths in your creation.
Or maybe overthink would be more appropriate….
[UPDATE] I’ve written a followup about why an over-thought solution like the one proposed here can be / is a good thing. And just to be blazingly, obviously, painfully clear on the matter. I do not think that every problem should be over-thought to the degree I took this. My solution represents a crazy amount of code for such a small problem. It’s intended as an example of how I’d mentally approach a real and complex problem presented by a client.
I was reading some articles yesterday that finally made the light bulb go off about distributed source control management (scm) and why we should be using them. First off, a distributed scm, unlike CVS or Subversion, has no central repository that all others pull from. It’s possible to set one up and say that it’s the master and tell people to pull from and push to it but that’s more a matter of convention. What’s truly unique about these systems is that each checkout is it’s own self-contained ecosystem. And there are many reasons this is a good thing:
Back in January of 2006 Ezra Zygmuntowicz came up with an exceptionally cool Rails plugin that, IMNSHO, should be in rails core. It’s called ez_where and it’s svn repo is here.
What’s so cool about ez_where? Well, the to really understand it’s beauty you have to step back to one of core concepts that’s at the heart of frameworks like Rails: Database Abstraction and Object Relational Mappings. Before these concepts really came into their own we were all writing raw SQL commands in our apps. Now we interact with a layer of abstraction that lets us work with the objects we’re actually programming with instead of database structures. Except, that’s not quite true with Rails. With rails you end up writing things that are possibly more complex than the SQL statements we’ve been trying to avoid. Here’s a particularly egregious example from a ticket system I’ve been working on:
The cranium of a good developer is filled with ideas for new applications. Most of them tend to bounce around with little energy and eventually succumb to entropy. Some ideas are made out of bouncier stuff and eventually reach escape velocity, at which point they are launched down the arms and funneled out the fingertips. You can tell just how cool an idea is by the speed of typing relative to the developers average words per minute.
Update: This article was written years ago, however, the information still holds true. What I would note is that these days both XML-RPC and SOAP have excellent libraries which makes working with both fairly simple. This article is about the capabilities of the two technologies, however, in my experience the question is no longer one of capabilities. It’s a question of which one you need to talk to, or which one your framework has baked in. In most cases the answer is SOAP. However, if you’re considering writing your own API, my recommendation would be to seriously consider using XML-RPC. It’s far less complicated and bloated, and the combination will make your debugging efforts much easier in my not so humble opinion.
I was consumed with dreams about Stephen Hawking’s black hole entropy formula last night, which is frustrating because the math is, sadly, beyond me. But, I mention it to you today because, knowing so little about black holes my mind instead kept trying to change it into an formula to calculate the Financial Entropy of a webapp subscriber.
So, I put it to you, dear reader, have you, or any of your math enabled friends, come up with a formula for calculating the finincial entropy of a webapp subscriber? If you haven’t, but you could, there are many many entrepreneurs who would sing your praises and happily buy you a drink.
I’m not sure where I originally came across the extract_fixtures rake task (maybe here)but there’s nothing better than using real data to run your Rails unit tests. Well, real in the sense that it was generated by actually using your app. But there’s a problem with extract_fixtures. Once you get some real data to base your tests on you don’t want it to change because it would break your tests. So, after the first run extract_fixtures becomes almost useless because it’ll wipe out the fixtures you’ve been working with.
Ever since migrations were introduced to Rails I’ve heard nothing but praise for them, and truth be told, they are a far better way of setting up your database than the standard raw sql import. But, that’s where the goodness ends.
The problem is in the concept of going up or down in database versions. The core concept is great, to be able to roll back to a previous version of the database, but the implementation is completely out of sync with the version control systems we use to manage the codebase that depends on that database. I’ll use subversion as an example because (for those of you still stuck in CVS land) every time you do a check in the system gets tagged with a new revision number.

{kind=link}
{kind=link}